◎賴文智、王文君
當企業在董事會上討論數位轉型、導入人工智慧或推動資料驅動策略時,議題往往會快速從「要不要做」走向「做了之後怎麼控管」。董事會真正需要面對的通常不是技術是否可行,也不是市場是否有需求,而是一個更根本的問題:我們的資料治理,是否足以承擔AI法律風險?
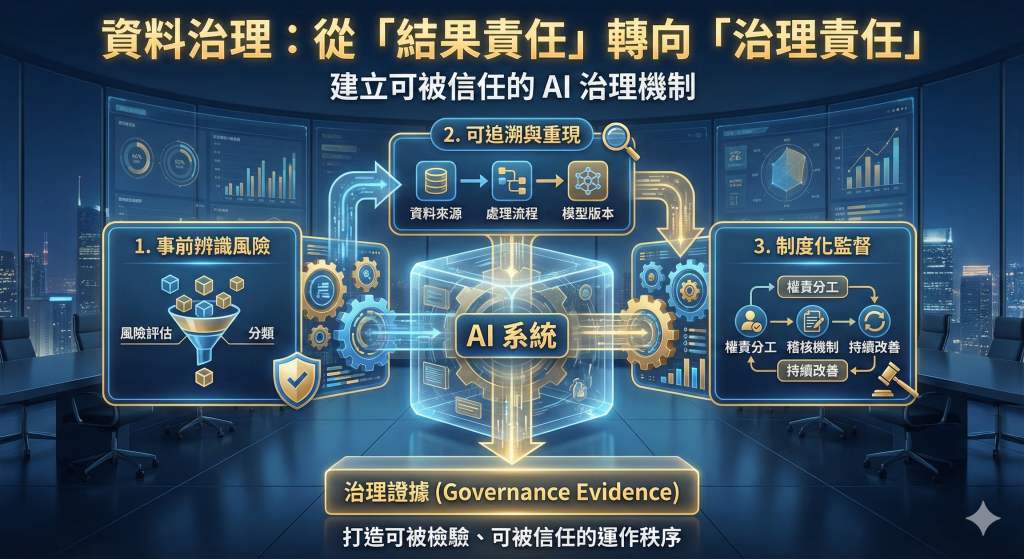
這個問題之所以成為董事會層級的問題,原因並不複雜。首先,資料與AI已經不再是單一部門的工具,而是企業營運邏輯的一部分:行銷要靠資料做精準投放、風險控管要靠模型做預測、供應鏈要靠演算法做排程、人資也可能用AI系統輔助做篩選與評估。當資料與模型開始直接影響決策與結果,企業對外造成的影響也隨之放大。其次,資料與AI的風險並非只存在於「有沒有違反個資法」這種單點問題,而往往牽涉到多重法律責任的交錯:個人資料、營業秘密、著作權、契約義務、消費者保護、競爭法、甚至反歧視與公平交易等。第三,也是最關鍵的一點,AI時代的不確定性,正在改寫企業被檢驗與被問責的方式。亦即,未來企業被檢驗的不是「一次決策是否正確」,而是「是否建立可被信任的制度」。
企業在AI時代真正必須具備的,不是承諾「永遠不會出錯」,而是能夠在事後被檢驗時回答三個問題:1.是否有事前辨識風險?(資料與用途是否經過風險評估與分類);2.是否有能力追溯與重現?(資料來源、處理流程、模型訓練與版本是否可追蹤);3.是否有制度化的控制與監督?(權責分工、核准流程、稽核機制、例外處理與持續改善)
這三個問題共同指向一件事:企業能否提出足以被外部信任的「治理證據」。也就是說,AI時代的企業責任,正在從「結果責任」逐步轉向「治理責任」。董事會與高階管理層應該要問的,不再只是「這個AI方案能幫我們賺多少」,而是「我們是否能承擔它帶來的法律風險與社會風險」。
在許多企業內部,資料治理常被誤以為是資訊部門的資料管理工作,或被簡化為一套資料政策文件。然而,在AI應用情境下,資料治理的本質是權力與責任的安排:誰有權決定哪些資料可以用、用於何種目的、要符合哪些限制、以及出事時誰負責、如何還原過程、如何修正。簡言之,當企業導入AI相關系統或服務時,真正會被放大檢視的通常不是演算法的數學公式,而是:1.資料是怎麼來的(合法性、來源、授權、同意與告知);2.資料被怎麼處理(去識別化、清洗、標註、品質控管、是否在授權範圍內);3.資料被怎麼使用與分享(目的限制、外部提供、委外處理、跨境流通、對外提供服務);資料與模型的關係如何被記錄(資料血統、版本控管、訓練紀錄、監督與稽核)。
因此,如果企業沒有建立系統性的資料治理,就很容易發生一種常見但危險的情境:AI系統的輸出已經被拿來做重大決策,但企業事後卻無法清楚說明「依據哪些資料、經過什麼處理、由誰核准、是否符合限制」。在這種狀況下,企業面對的不只是符合法令規範風險,更是治理正當性與社會信任的風險。
本系列的文章希望探討的議題,並不是「資料治理是什麼」,而是「企業如何建立可問責的資料治理機制」。董事會與管理層需要一套能夠落實在組織運作中的法律治理框架。這套框架必須同時做到:1.讓資料成為可用的營運資產(品質、可用性、共享、價值);2.讓資料使用可被法律與監理系統接受(合法性、限制、證據化、可稽核);3.讓AI應用可被社會信任(透明度、公平性、人類監督、可追溯、可修正)。
因此,本系列文章將以「企業資料治理的法律面向」為主軸,將資料治理放回企業治理與法律責任的脈絡中,系統性說明企業在資料經濟與AI時代所面臨的關鍵法律挑戰,並提出可操作的制度設計與導入方式。讀者將在後續文章中看到,資料治理不是一份文件,而是一套由人員、流程、權責、控制點、紀錄與稽核所構成的治理系統;而透過法律角度來進行資料治理的價值,正在於讓企業在高度不確定的環境中,仍能建立可被檢驗、可被信任的運作秩序。 資料之所以能創造價值,正是因為它可被擴散、被重複利用、被重新組合。但也正因如此,資料的法律風險往往呈現跨領域、跨法域、跨期間且難以抽離的特性。後續將以此為起點,說明資料在法律上為何會成為新時代的核心風險來源,以及企業推動資料治理時究竟要治理的「是什麼」。
