◎賴文智律師
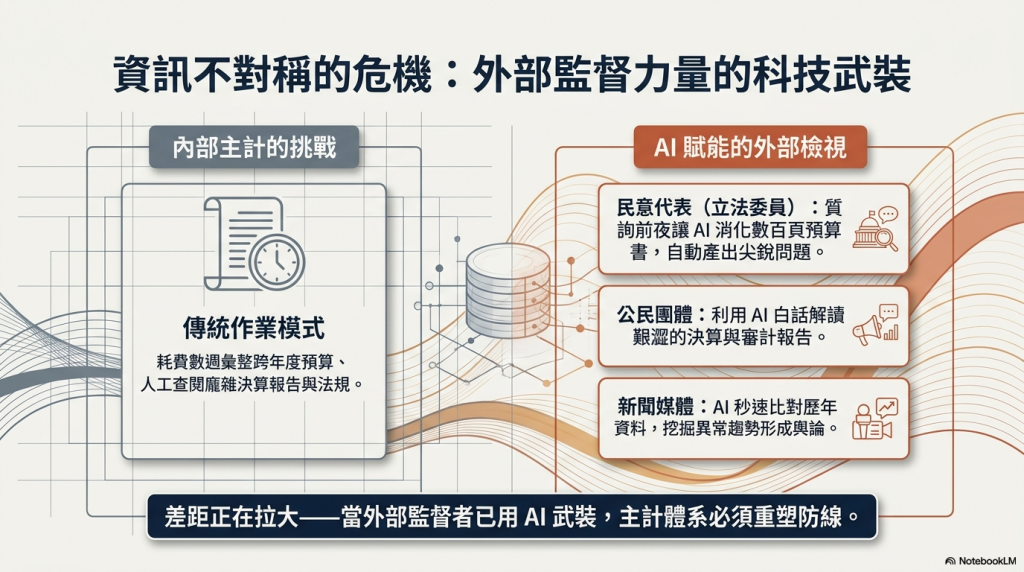
談到生成式AI,許多人第一個反應或許是「那是科技人的事」、「我又不是工程師」。然而,對主計人員而言,與生成式AI的距離正在以遠超預期的速度縮短。由主計人員自身的工作場景出發,生成式AI早已能在多項繁複作業中扮演助理角色。例如,在預算編製與審查時,AI可以彙整跨年度資料、自動產出說明草稿,將原本動輒耗費數週的匯整工作大幅壓縮;在統計分析上,AI能快速摘要海量資料、產生圖表初稿並提出趨勢解讀;在法規查詢上,AI能即時檢索預算法、會計法、審計法相關條文及函釋,協助釐清個案處理方向;至於公文與報告撰寫,AI在草擬、潤稿、翻譯與格式校對上的能力已日趨成熟。對於長年面對龐雜資料、高密度文書工作的主計人員而言,這是一波貨真價實的生產力革命。
但故事的另一面更值得警覺。與主計業務相關資訊的外部使用者,像是立法委員的助理、新聞媒體、公民團體乃至一般民眾,正在以前所未見的方式使用生成式AI。立委助理可以在質詢前夜,讓AI將厚達數百頁的預算書消化、比對、整理出一連串尖銳問題;公民團體與民眾,過去看不懂的決算與審計報告,現在可以丟給AI解讀後再回頭發問;新聞媒體則能藉由AI比對歷年資料、挖掘異常,形成輿論監督。當外部的監督力量已經開始用AI,主計人員若仍停留在傳統的工具與思維,差距只會越拉越大。主計人員必須比過去更熟悉AI,才能因應更專業的監督與提問。
一、AI與生成式AI
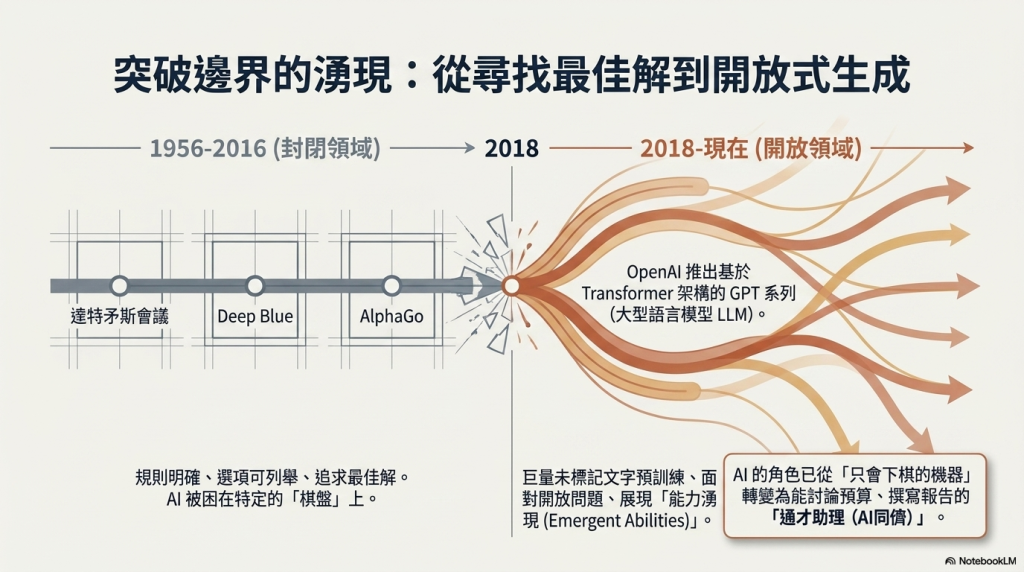
要理解今天生成式AI帶來的衝擊,可以先簡單回顧AI的發展。傳統AI的源頭可以追溯到1956年的達特矛斯會議,從Rule-based系統、專家系統,到打敗西洋棋世界冠軍的Deep Blue,再到2016年AlphaGo擊敗李世乭,這一脈絡中的AI都有一個共同特徵:「封閉領域、求最佳解」。也就是說,問題的規則明確、選項可被列舉,AI在限定條件下找出最優或相對好的解,演算到一定步數後,人類就贏不了。但這類AI的應用範圍是有明確的領域界線,AI很強但卻只能被設計應用的那塊棋盤(領域)上強,所以,發展到頂點,就必須轉向其他不同領域。
2018年可說是AI技術發展的重要分水嶺。OpenAI推出基於Transformer架構的GPT系列模型,正式開啟大型語言模型(LLM)的時代。生成式AI改變傳統AI領域的遊戲規則:它面對的是開放問題,並以巨量未標記文字進行預訓練,能生成類似人類自然語言的內容。更令人驚訝的是所謂「能力湧現(Emergent Abilities)」的現象,當LLM搭配Big Data訓練資料規模到達一定程度後,連訓練資料較少的領域也展現出預測與生成的能力。
換言之,過去AI可能只是一台只會下棋的機器,今天基於大型語言模型的生成式AI,因為人類多數的外顯知識都是以「語言」、「文本」的方式呈現,基於處理開放式問題的聊天工具,慢慢變成能跟你討論預算、撰寫報告、回答法規問題、甚至是挑出資料中潛在問題的「通才助理」,甚至可說是「AI同儕」。這也正是它會被廣泛應用、進而帶來大量法律與治理議題的根本原因。
二、從生成式AI與傳統AI的差異理解風險的緣起
人工智慧(AI)這個具有歷史的詞語,其實也代表技術發展的軌跡。過去為何人類只有透過科幻小說、電影描述人工智慧所帶來的風險?因為我們都知道離這一天還很遠。但生成式AI強大的問題回應能力,在這幾年將科幻小說中的恐慌帶進了現實。筆者認為理解傳統AI與生成式AI的差異,是我們理解生成式AI風險的最佳途徑。
首先,傳統AI在限定規則下找最佳解(西洋棋、影像辨識),所處理的是封閉型的問題;生成式AI則在開放式問題下生成相對適合的解(撰文、摘要、對話),若沒有特別限制,什麼樣問題都會給予回應。我們就可以理解為什麼我們會覺得前者像是計算機,會提供像Yes或No這種明確的答案;後者則更像是顧問,會依據你的問題給予回覆,但卻未必能解決你的問題,只是必然會有回應而已。
其次,二者在輸出或生成回應時特性完全不同。傳統AI在相同輸入下必然會產生相同輸出,可驗證、可稽核;生成式AI使用時,相同輸入卻可能生成不同輸出,其原因可能在於生成式AI可能因為猜測第一次的生成成果你可能不滿意,所以,會換個關聯性的路徑生成回應,看看是不是會更符合你的需求;甚至,可能其他使用者的使用,也會非常間接影到你下一次相同問題的回應生成。亦即,生成式AI在「生成」時,主要是受到其模型、參數、權重及你的使用行為的各種關聯性的影響,不是嚴格依據邏輯法則運作,甚至要教會生成式AI各種真實世界的邏輯都很辛苦,但這並不妨害生成式AI回應你的需求。這也是一般所稱「幻覺」(hallucination),一本正經地說胡話、編造資料、引用不存在的條文等產生的原因。對需要精確、可稽核的主計工作而言,這個技術上的差異絕不能忽視。
最後,傳統AI因為追求正確性,通常需要專業團隊建模,限制應用於特定場域,通常影響範圍都是可控的,最多就是不使用;但生成式AI在模型運作不需要依賴訓練資料,只要廠商擁有足夠的算力,就可以透過網路提供予任何人使用,而LLM因為以人類知識的文本為訓練基礎,也會讓人感受到幾乎什麼類型的問題都可以問,可說是應用無邊界。這意味著機密外洩、著作權爭議、責任歸屬等風險,可能在難以控制的情形下擴大到組織的每一個角落。當每位同仁都可以打開瀏覽器跟AI對話時,組織的資訊管理邊界其實已經被悄悄重劃。
三、為什麼生成式AI會產生幻覺?
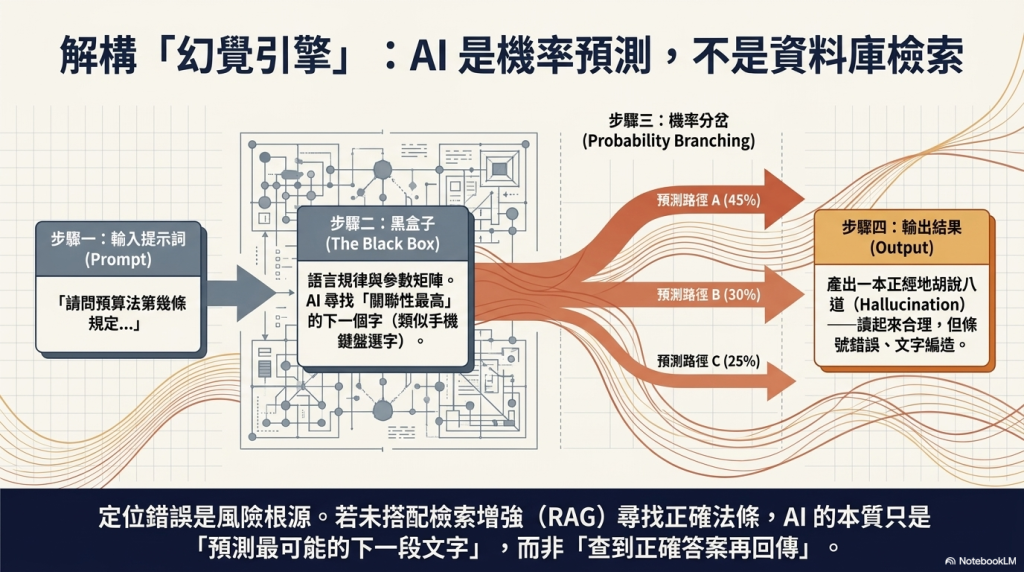
接下來我們就來處理一個大家最關心的議題,「生成式AI為何會犯錯?」第一個原因,我們需要理解生成式AI並不是「查資料」,而是「預測」關聯性高的下一步。比較容易想像的例子是像我們手機的輸入功能,為了加速輸入的速度,我們打字時會跳出幾個下一個我們可能會輸入的備選字,如果剛好對了,我們只要點選即可,這些備選字就是與我們前面輸入關聯性高的字詞。我們可以想像LLM很像是一個超大的空間,將字詞與字詞間的關聯性變成量化的參數與權重。我們對生成式AI輸入的Prompt內容,生成式AI就提供關聯性最高的回應。亦即,生成式AI是透過機器學習與演算法,對輸入資料產生預測或內容輸出,本質不是資料庫查詢,而是依據過去學習資料「預測最可能的下一段文字」。它的運作邏輯是依語言規律與機率,生成「看起來合理」的內容,而非「查到正確答案再回傳」。
所以,如果使用者將生成式AI當作跟我們習慣的Google搜尋、法規資料庫查詢一樣來使用時,例如:主計同仁問chatGPT,「請問預算法第幾條規定是什麼?可否應用在某某類型的案件中?」AI回給你的可能是一段「讀起來很像真的」但條號錯誤、文字編造的答案。當然,這可能隨著生成式AI服務技術的進步而有所改善,例如:某些生成式AI服務即使我們沒有特別要求,還是會偷偷上網先查一下,找到正確的法條內容,再進一步生成回答,而不是真的完全從無到有以機率、關聯性的方式生成。簡言之,生成式AI的錯誤,可能一開始是源於「定位」的錯誤,就是「用錯了」,這種情形以適切的方式使用或是將之用於適切的地方,就可以相當幅度改善生成式AI的「幻覺」。
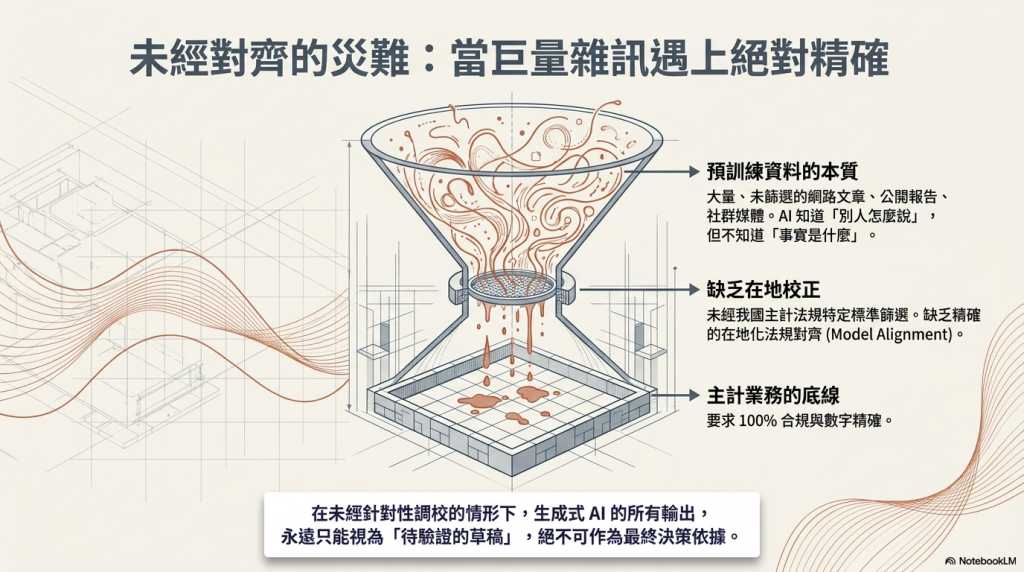
第二個原因在於多數生成式AI模型預訓練資料,本質是大量、未針對特定應用需求進行篩選的資訊。無論是封閉式或是開源的AI模型,往往預訓練的資料必須非常龐大,若是蒸餾自其他AI模型,其實也是間接地受到這些未經特別篩選的資料,像是網路文章、書籍報告、各類公開資料、社群媒體資料等,但這些資料未經特定標準的精確篩選與在地法規校正,其結果就變成生成式AI可能知道很多文本曾經出現過什麼(知道很多人怎麼說),但不知道事實如何,沒有特別針對性的訓練,也不知道什麼是對的。
當然,隨著AI業者投入研發,生成式AI服務也透過檢索增強(RAG)、強化學習、模型對齊等各種機制持續減少幻覺。但對於主計這種需要極高正確性的領域而言,若未針對性的訓練、調校,生成式AI的輸出永遠應該是待驗證的草稿、參考,而非最終答案。
四、AI對主計領域帶來的法律面影響
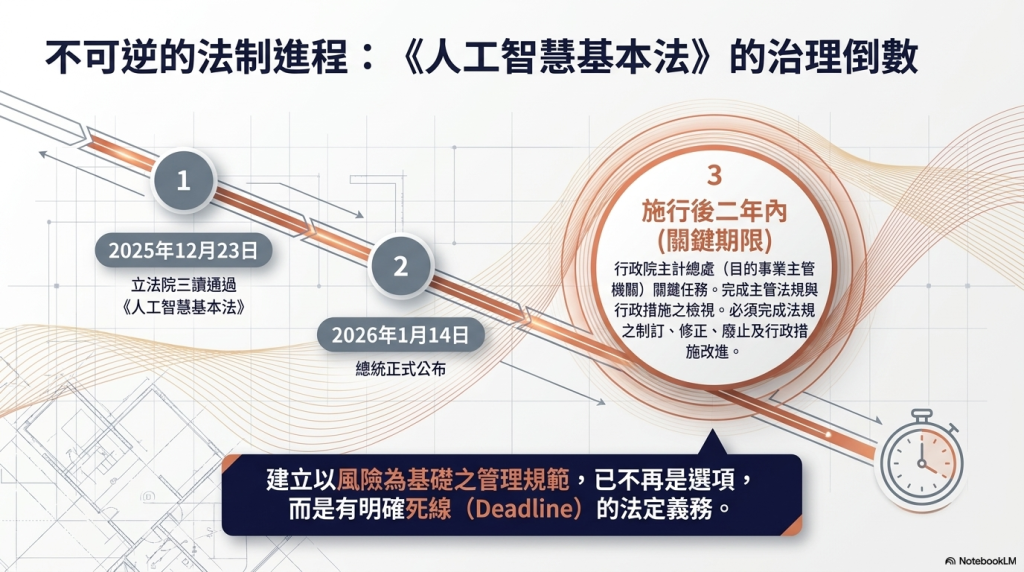
然而,隨著《人工智慧基本法》已於2025年12月23日經立法院三讀通過,並於2026年1月14日總統公布。無論我們是否願意,都必須正視AI時代已經來臨,任何人都難自外於AI對我們的影響,因此,即令是較為嚴謹、傳統的政府主計領域,我們也須正視生成式AI為主計工作帶來的法律衝擊。
(一)AI不只是技術,而是公務環境與工作思維的重塑
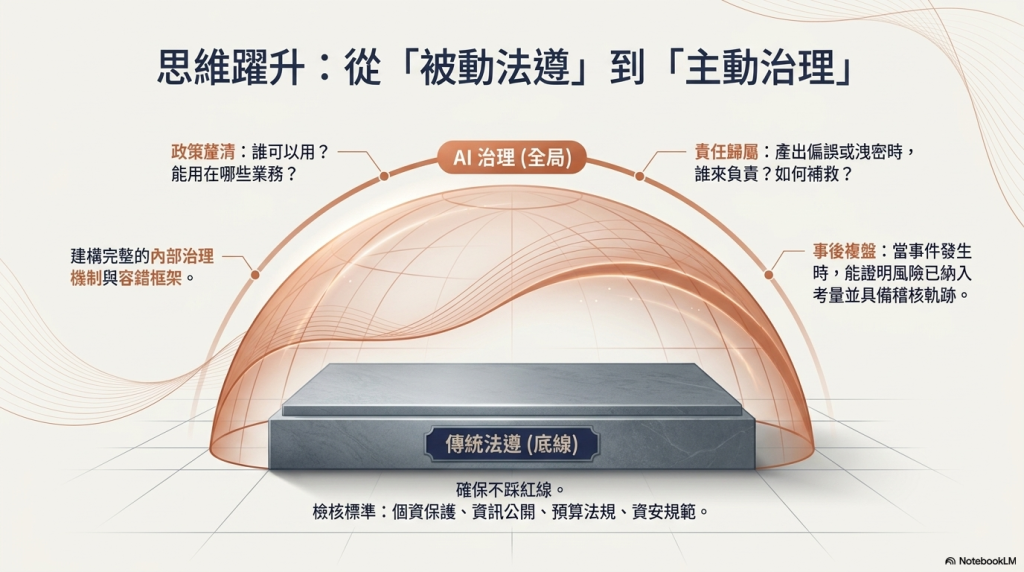
AI牽動社會運作,相關法規將大幅變動;公部門任務將被重新拆解、組合,人機分工與協作必須重新定義;外部的立委、媒體、民眾也將以AI提出更專業的監督與質詢。換言之,這不是「IT單位該想的事」,而是每位主計人員都必須直面的工作現實。更重要的是觀念層級的升級,我們必須從「傳統法遵」到「AI治理」全面升級。
「法遵」是指機關在運用AI時,是否符合個資、資訊公開、預算、會計、資安等既有規範。這是底線,是不能碰的紅線。「治理」則更進一步必須具體說明機關內部AI政策為何?誰可以用、用在哪些業務?權責、稽核與責任歸屬如何安排?AI產出有偏誤、有錯誤、甚至涉及洩密時誰來負責、如何說明、如何補救?不只是合不合法的問題,而是機關有沒有一套完整的內部治理機制,因應當AI相關事件發生時,確認該等事件的風險是否曾被納入考量,並可以事後複盤檢驗。
(二)行政院主計總處是主計業務的AI主管機關
《人工智慧基本法》中央主管機關為國家科學及技術委員會,涉及各目的事業主管機關職掌者,由各目的事業主管機關辦理;人工智慧風險分類框架由數位發展部訂定。各目的事業主管機關須訂定以風險為基礎之管理規範。
而目的事業主管機關應依《人工智慧基本法》第18條規定,檢討所主管之法規與行政措施;有不符合本法規定或無法規可適用者,應自本法施行後二年內,完成法規之制(訂)定、修正或廢止,及行政措施之改進。行政院主計總處對於主計業務與人工智慧相關議題及法規的檢視,同樣需要在施行後二年內完成。
(三)從AI治理原則檢視主計業務的法律風險
《人工智慧基本法》第4條所揭櫫之AI治理原則,其實就是檢視主計業務在進入AI時代可能面臨法律風險的標準。筆者試著從將AI治理原則落實在政府主計業務導入AI時可能需要思考的議題,簡單舉例如下:
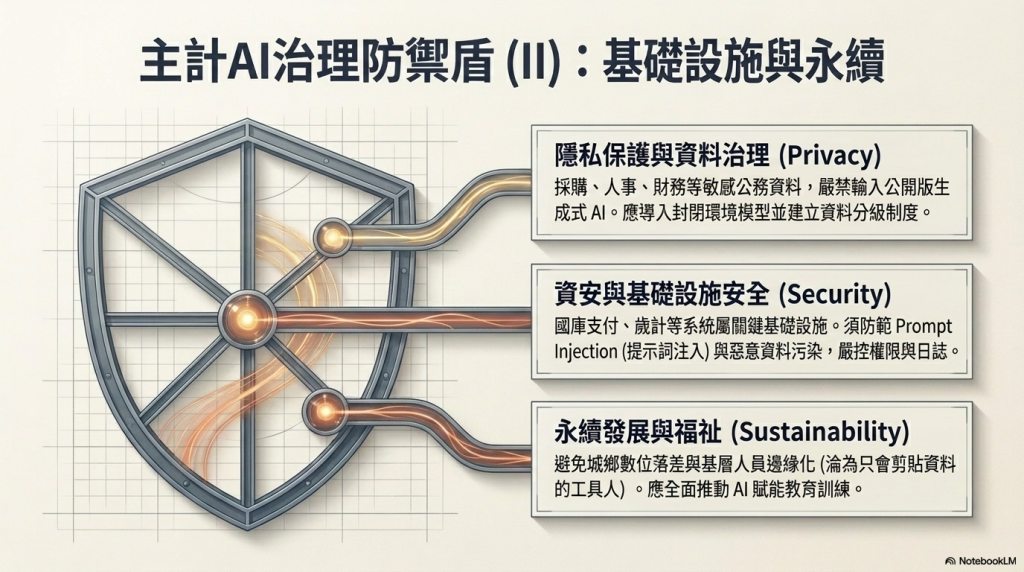
- 永續發展與福祉:主計總處可能要思考AI的導入會不會造成基層行政人員被邊緣化?如果導入生成式AI後,現有員工不會使用、偏鄉機關沒有能力導入、基層只剩剪貼資料餵給AI,就可能形成新的數位落差。AI教育訓練、建立AI使用SOP、降低不同機關間的能力差距等,即必須納入思考。
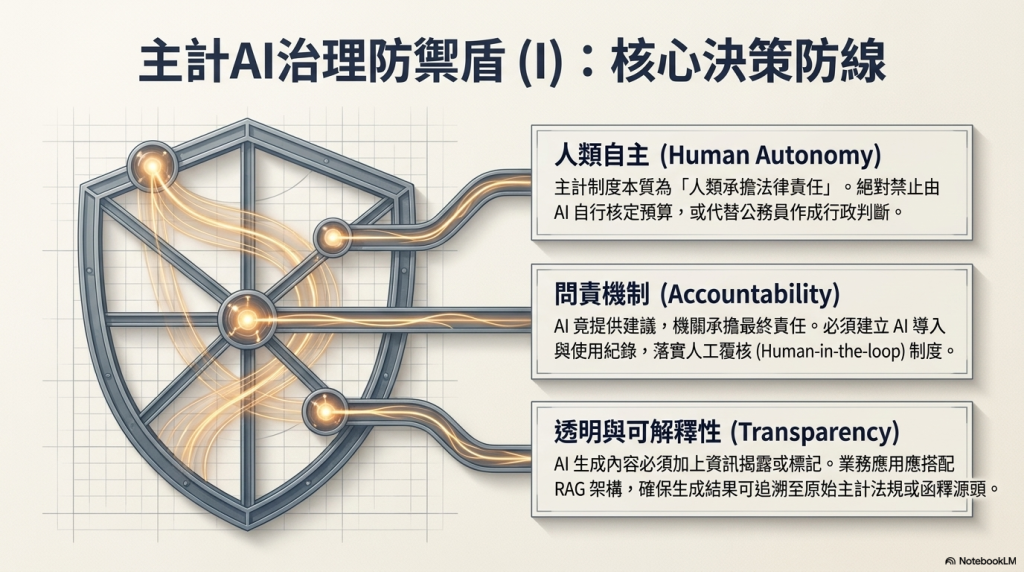
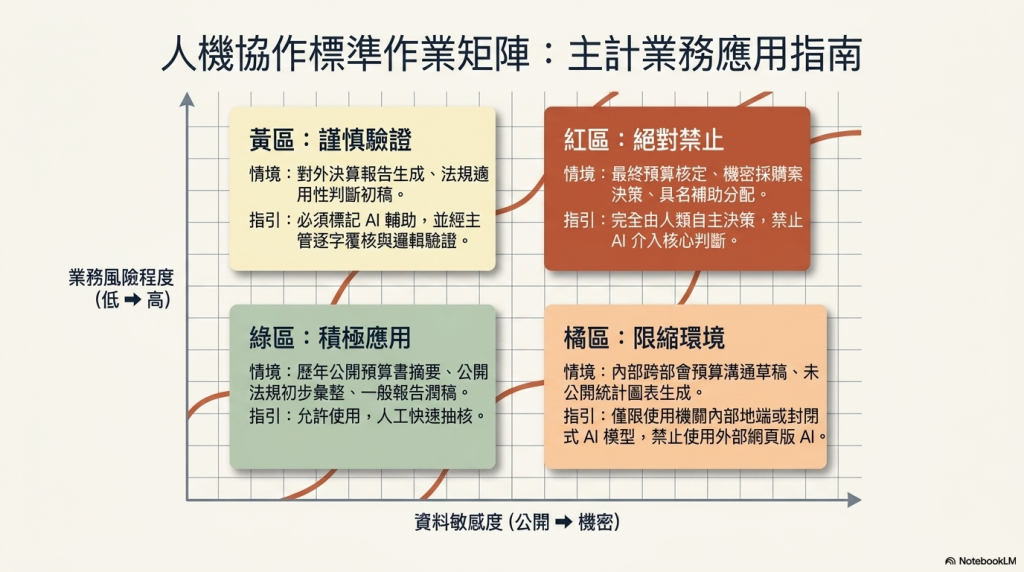
- 人類自主:這是主計體系最核心的原則,因為主計制度本質上就是「由人類承擔法律責任」。不能由AI自行核定預算、不能由AI直接決定是否合法、不能由AI代替公務員作成行政判斷,應該是主計業務AI治理的絕對原則。
- 隱私保護與資料治理:主計資料經常涉及公務資料、採購資訊、人事資料、補助資料、財務資訊等,最大的風險就是把敏感資料送進外部模型,因此,禁止直接使用公開版生成式AI、導入封閉環境的AI模型、建立資料分級制度,都是必須考量的重點。
- 資安與安全:主計系統涉及國庫支付、政府歲計、地方財政系統等,是國家重要基礎設施的一部分。如果所導入的生成式AI遭Prompt Injection、資料污染、惡意訓練等,都可能產生嚴重影響。AI系統權限控管、日誌紀錄、模型來源審查、資安測試、委外管理等都必須納入AI治理的範疇。
- 透明與可解釋:AI生成內容應做適當資訊揭露或標記,已幾近屬於法律義務。對於主計業務而言,搭配RAG或類似架構,儘量實現由AI生成的結果可以追溯源頭,是比較合理的做法。
- 公平與不歧視:主計業務可能涉及對於補助分配、社福統計、預算資源配置等規劃與查核,AI若使用過去資料學習,可能會放大過去資料中的偏誤。但是,也可能使用AI其實是更容易發現過去潛藏的不公平與歧視。二種角度都應思考。
- 問責:這是AI治理的核心,AI可以提供建議,但責任仍屬於機關。因此,AI導入、使用的紀錄、人工覆核制度、誰該負什麼層級的責任,應該都要在AI治理的架構中說清楚。
五、結語
《人工智慧基本法》通過後,政府機關不論主動或被動,皆須直面AI議題。這不再是想不想用AI的選擇題,而是在AI時代如何履行公務的申論題。對主計人員而言,目前的功課並不是去成為AI專家,而是要建立面對AI時代的基礎能力。
首先,理解AI能做什麼、不能做什麼,尤其是生成式AI,不能因為其能力看似強大,就覺得它什麼都能做,應該是要把它放在合適的位置使用;其次,必須認知到AI治理將會取代過去被動的法規遵循,即令現在可能還沒有相關的制度,每一個人都應該建立針對公務AI使用的紀錄,讓每一次AI輔助的決策都有可問責的軌跡;第三,必須理解到委外單位可能使用AI,應將委外單位納入AI治理的範疇;第四,必須為更專業的外部監督做好準備,因為立委、媒體與民眾,已經開始用AI來針對主計業務做功課。相信每個人都可以找得到與AI共好的模式。